Amazon Forecast × WebFOCUSで予測分析してみた
昨今、AI(人工知能)やML(機械学習)が話題になっていますよね。
そこで今回は、AWSの機械学習を用いた予測分析サービスである、「Amazon Forecast」(以下、Forecast)というサービスで予測分析した結果を、WebFOCUSで連携して表示できるかを検証してみました!
結論から言いますと、簡単な操作で連携ができ、Designerを使った視覚的なグラフが作成できました!(操作はすべてGUIで完結します)
少しでも気になりましたら以下をご覧ください。
Amazon Forecast は、統計アルゴリズムと機械学習アルゴリズムを使用して、非常に正確な時系列予測を実現するフルマネージドサービスです。Amazon.com における時系列予測に使用されているのと同じテクノロジーに基づいている Forecast は、履歴データに基づいてfuture state-of-the-art 時系列データを予測するためのアルゴリズムを提供します。
機械学習の経験は必要ありません。
時系列の予測は、小売、金融、物流、ヘルスケアなどの複数の分野で有益です。Forecast を使用して、在庫、労働力、ウェブトラフィック、サーバー容量、および財務に関するドメイン固有のメトリクスを予測することもできます。
https://docs.aws.amazon.com/ja_jp/forecast/latest/dg/what-is-forecast.html
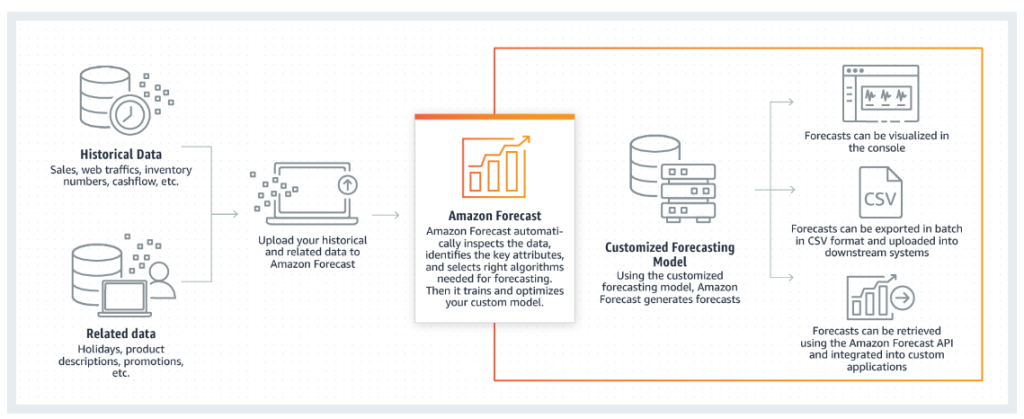
- 自動機械学習 – Forecast は、データセットに最適な機械学習アルゴリズムの組み合わせを見つけて、複雑な機械学習タスクを自動化します。
- State-of-the-art アルゴリズム – Amazon.com で使用されているのと同じテクノロジーに基づく機械学習アルゴリズムの組み合わせを適用します。Forecast は、一般的に使用される統計手法から複雑なニューラルネットワークまで、幅広いトレーニングアルゴリズムを提供します。
- 欠落値のサポート – Forecast では、データセット内の欠落値を自動的に処理するためのいくつかの filling メソッドが用意されています。
- 追加のビルトインデータセット – Forecast は、モデルを改善するためにビルトインデータセットを自動的に組み込むことができます。これらのデータセットは既に特徴エンジニアリングされており、追加の設定は必要ありません。
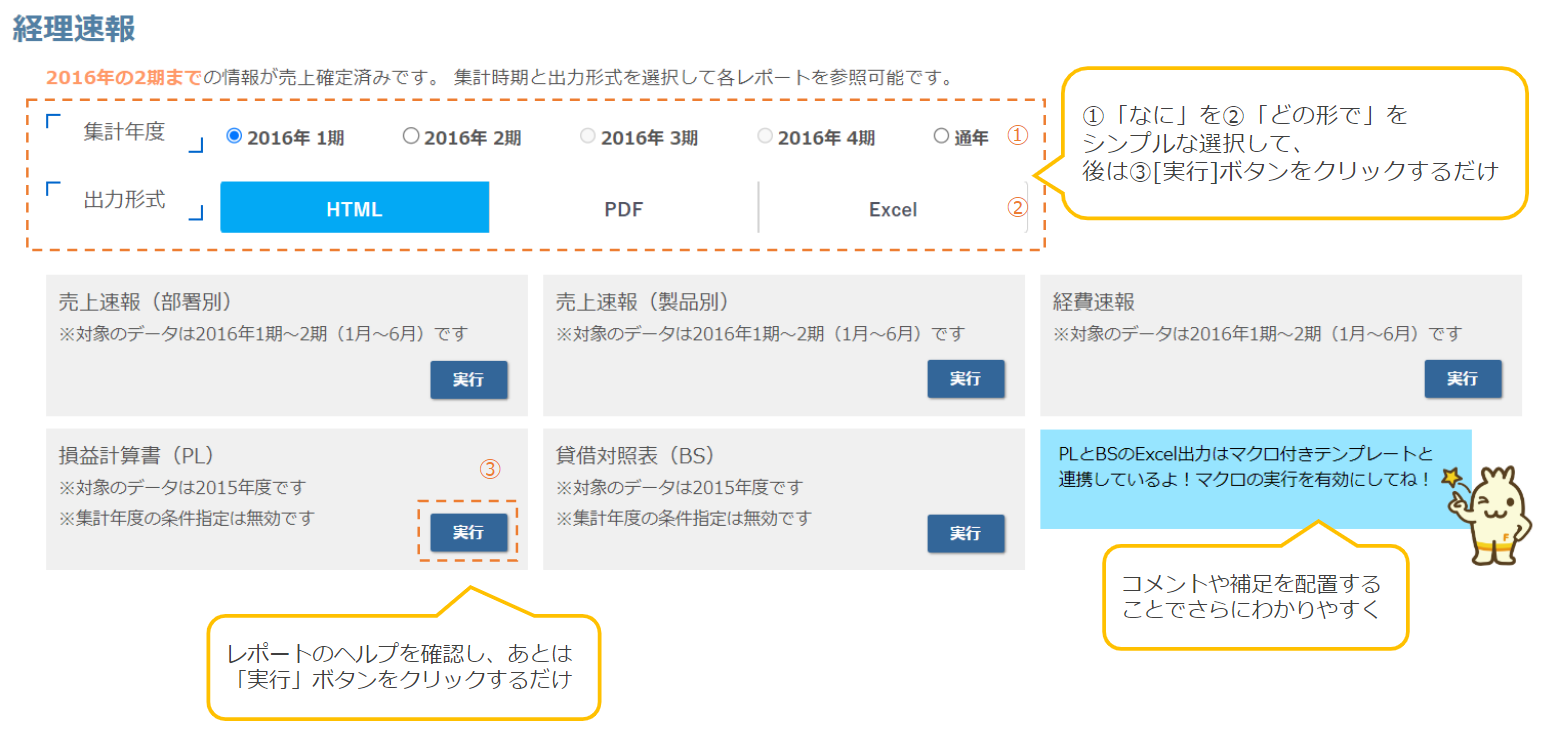
1.本検証の構成イメージ
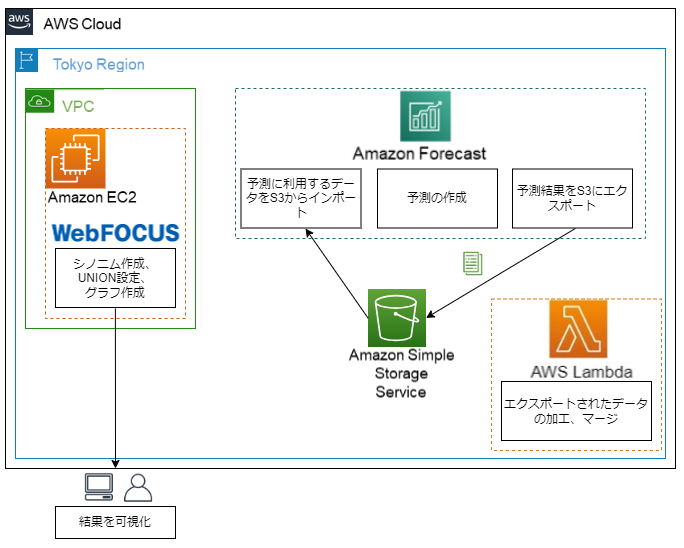
1.Forecastで予測に利用するデータをS3からインポート
2.Forecastで予測を作成
3.予測結果をS3にcsv形式でエクスポート
4.Lambdaでデータの加工、マージを行いcsv形式出力
5.WebFOCUSでcsvに対してシノニム作成、実績値と予測値のUNION設定、グラフを作成
2.予測データをエクスポートする(Forecast操作)
※Forecastで予測データの生成(Generate forecasts)までが完了している前提での手順です。
Forecastで実行した予測分析結果を、S3の任意のバケットにcsv形式でエクスポートします。
Forecastでエクスポートした場合、対象のバケット内には予測分析結果となるcsvファイルが、約50行ごとに区切られて複数ファイルが生成されます。
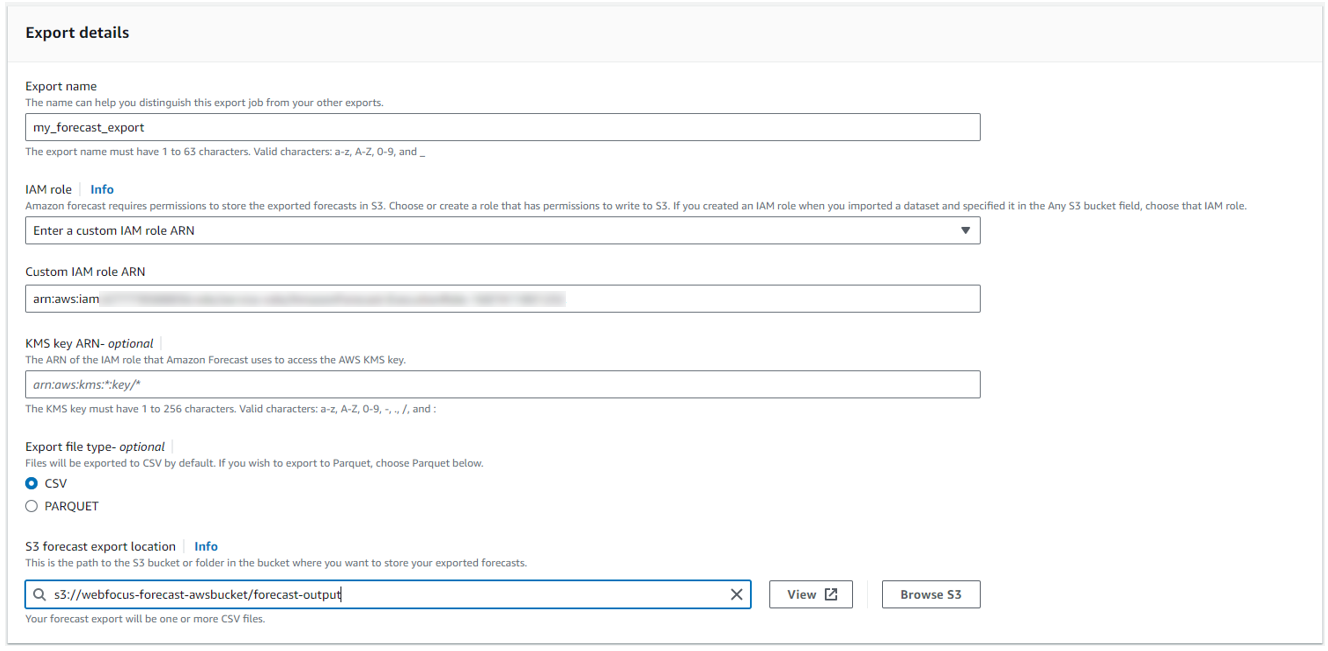
予測分析結果をS3バケットにエクスポート。
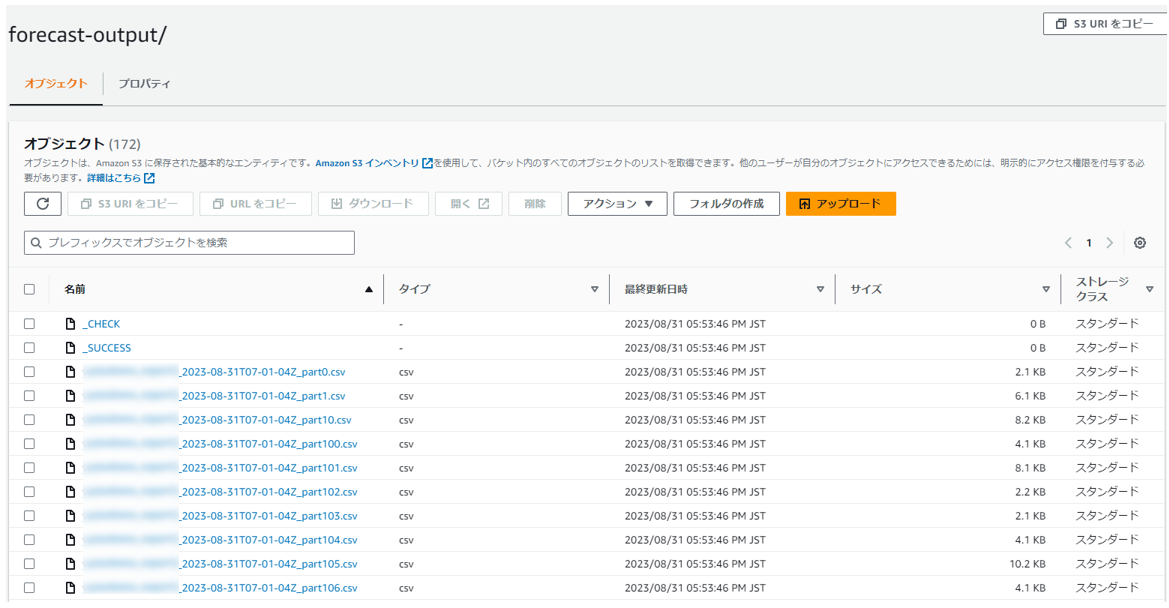
予測分析結果となる複数のcsvファイルがバケット内に生成されます。
※本手順では「forecast_output」フォルダにエクスポートします。
3.S3バケット内の複数のcsvファイルを1つのcsvファイルにマージする(lambda側操作)
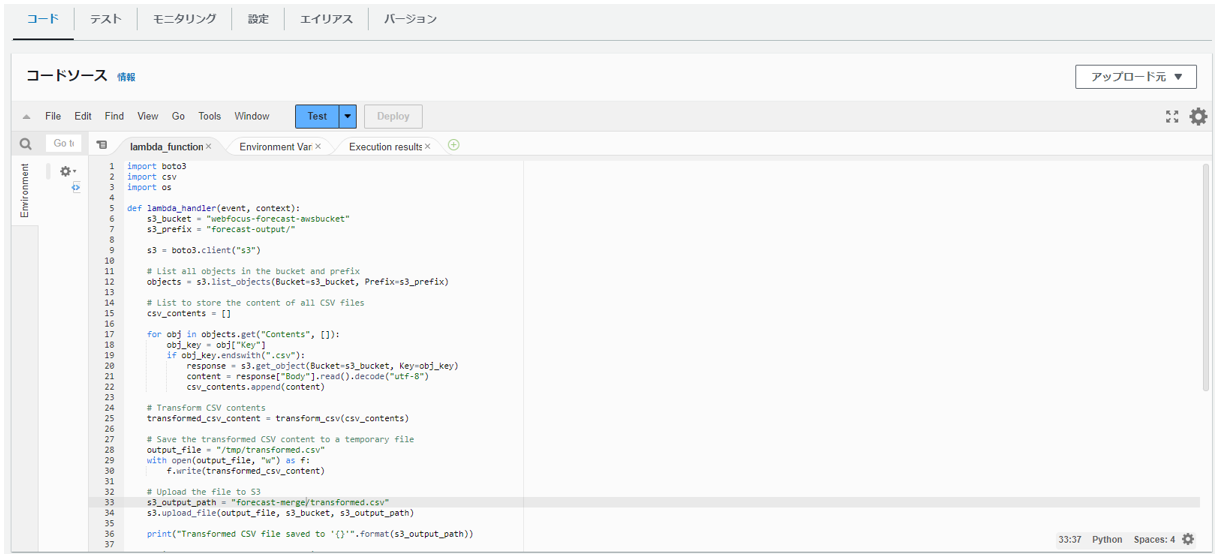
lamdaを起動し、ソースコードを実行してS3バケット内の複数のcsvファイルを1つのcsvファイルにマージします。
マージする際、項目名を先頭行だけ残す、日付データのいくつか文字を置換する加工を行っています。
import boto3
import csv
import os
def lambda_handler(event, context):
s3_bucket = "webfocus-forecast-awsbucket"
s3_prefix = "forecast-output/"
s3 = boto3.client("s3")
# List all objects in the bucket and prefix
objects = s3.list_objects(Bucket=s3_bucket, Prefix=s3_prefix)
# List to store the content of all CSV files
csv_contents = []
for obj in objects.get("Contents", []):
obj_key = obj["Key"]
if obj_key.endswith(".csv"):
response = s3.get_object(Bucket=s3_bucket, Key=obj_key)
content = response["Body"].read().decode("utf-8")
csv_contents.append(content)
# Transform CSV contents
transformed_csv_content = transform_csv(csv_contents)
# Save the transformed CSV content to a temporary file
output_file = "/tmp/transformed.csv"
with open(output_file, "w") as f:
f.write(transformed_csv_content)
# Upload the file to S3
s3_output_path = "forecast-merge/transformed.csv"
s3.upload_file(output_file, s3_bucket, s3_output_path)
print("Transformed CSV file saved to '{}'".format(s3_output_path))
# Function to perform CSV transformations
def transform_csv(csv_contents):
# Create a new list to hold the transformed lines
transformed_lines = ["item_id,date,p10,p50,p90"]
# Iterate through CSV contents and transform
for content in csv_contents:
# Split the content into lines
lines = content.strip().split("\n")
# Skip the header line
header = lines[0]
# Iterate through data lines and transform
for line in lines[1:]:
fields = line.split(",")
if len(fields) >= 5:
item_id, date, p10, p50, p90 = fields
transformed_date = date.replace("T", " ").replace("Z", "").replace("-", "/")
transformed_line = f"{item_id},{transformed_date},{p10},{p50},{p90}"
transformed_lines.append(transformed_line)
# Combine the transformed lines into content
transformed_csv_content = "\n".join(transformed_lines)
return transformed_csv_content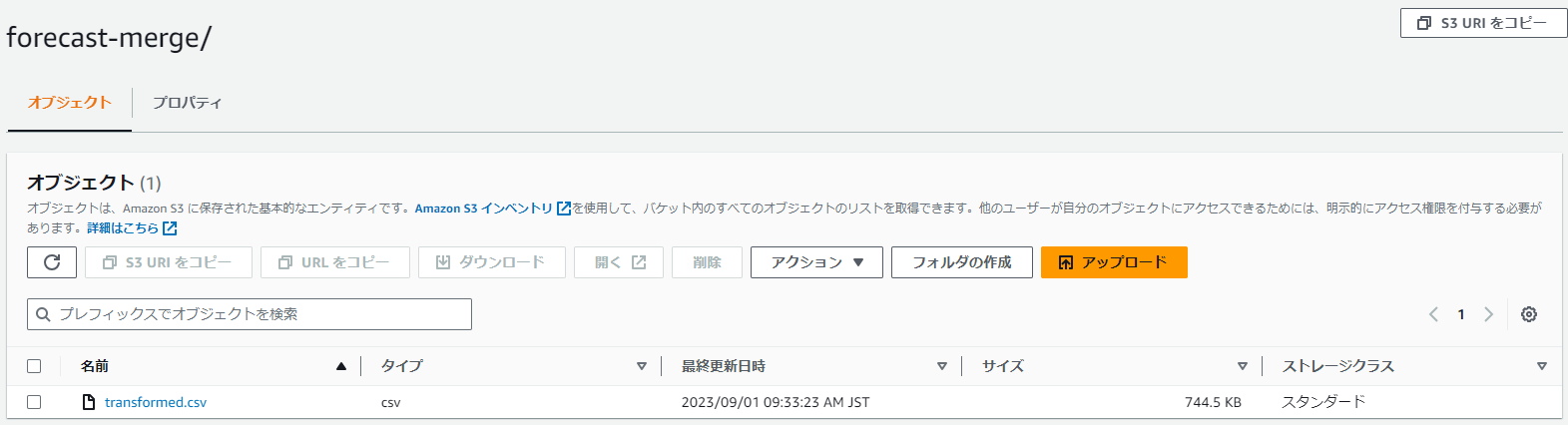
「forecast-merge」フォルダ内に「transformed.csv」というマージされたcsvファイルが生成されます。
4.WebFOCUSにS3のアダプタを設定する
Webコンソールにアクセスして、アダプタを設定します。
Webコンソールにアクセスし、「データの取得」をクリック。
+ ボタンをクリック。
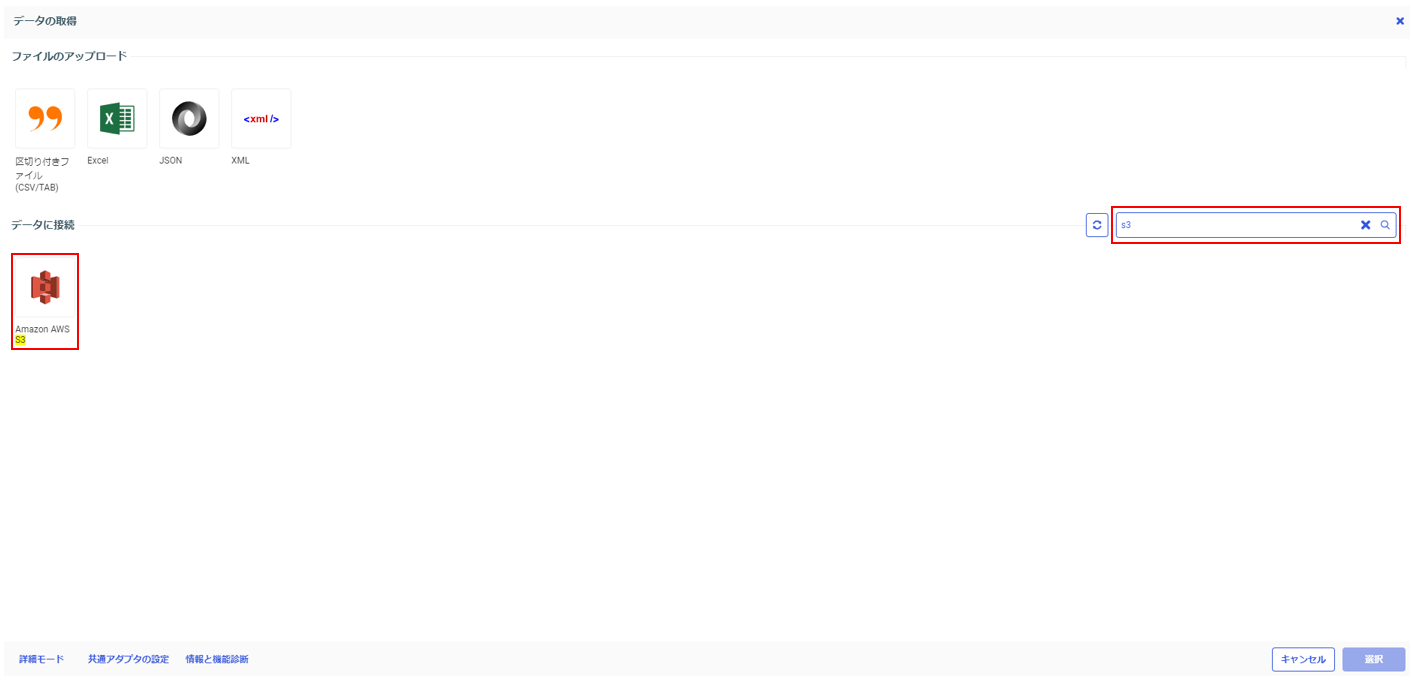
右側の検索ウィンドウで「S3」を検索。
表示されるアイコンをダブルクリック。

「新規作成」をクリック。
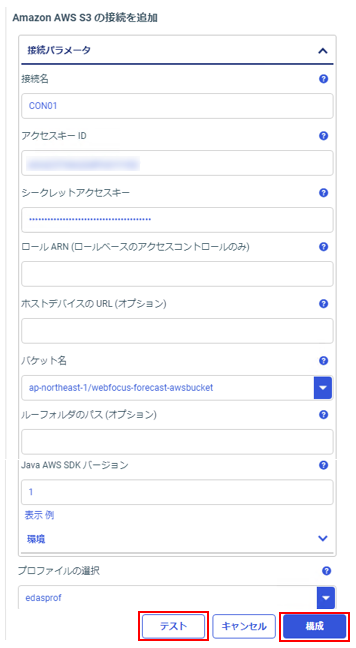
パラメータを入力。
入力が完了したら、「テスト」をクリックし、正常に接続ができたら「構成」をクリック。

「テスト」結果(成功時)。
| パラメータ名 | パラメータの概要 | 値(補足) |
|---|---|---|
| 接続名 ※必須 | WebFOCUSで利用する任意のアダプタ名 | (任意の値) |
| アクセスキーID ※必須 | AWSアカウントのアクセスキー | 「AKI~」で始まる値 |
| シークレットアクセスキー ※必須 | アクセスキーに紐づくシークレットアクセスキー | (利用中の値) |
| ロールARN | ロールの識別に使用するARN(Amazon Resource Name) | (利用中の値) |
| ホストデバイスのURL | ECSのURL | (利用中の値) |
| バケット名 ※必須 | 参照先のS3バケット名 | 「リージョン名/バケット名」 |
| ルートフォルダのパス | 選択したバケット内でルートとして使用するフォルダ | (利用中の値) |
| Java AWS SDK バージョン ※必須 | Java AWS SDKのバージョン(1 or 2) | 1(デフォルト) |
5.S3アダプタをアプリケーションディレクトリに割り当てる
作成したS3バケットのアダプタをアプリケーションディレクトリに割り当てます。
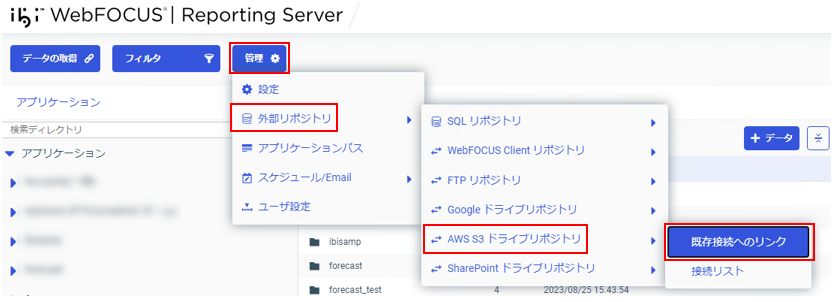
「管理」-「外部リポジトリ」-「AWS S3 ドライブリポジトリ」-「既存接続へのリンク」をクリック。
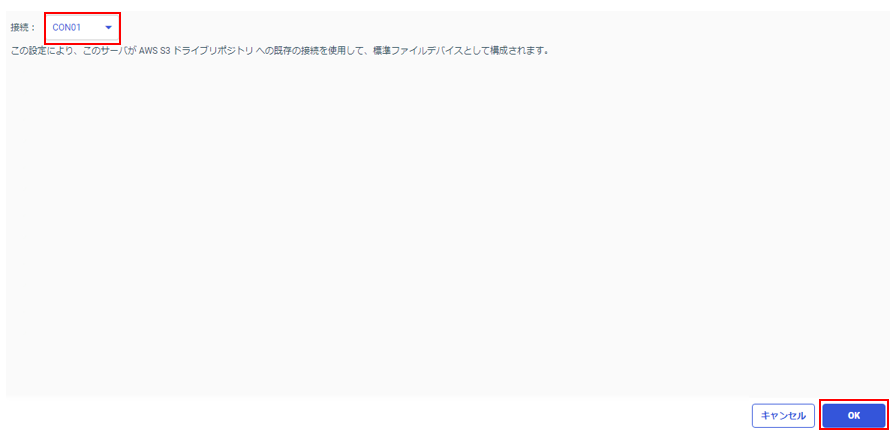
「接続」で該当の接続先を選択し「OK」をクリック。
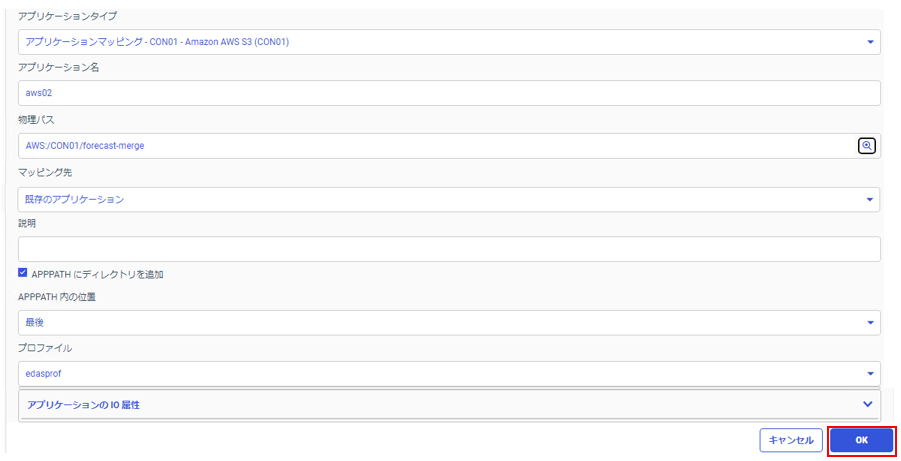
パラメータを入力。
入力が完了したら、「OK」をクリック。
| パラメータ名 | パラメータの概要 | 値(補足) |
|---|---|---|
| アプリケーションタイプ ※必須 | S3アダプタの接続名を選択 | CON01(本手順の場合) |
| アプリケーション名 ※必須 | 任意のアプリケーションフォルダ名 | aws02(本手順の場合) |
| 物理パス ※必須 | 参照先S3バケットのパス | AWS:/CON01/forecast-merge (本手順の場合) |
| マッピング先※必須 | マッピング先の状態を選択 | 既存のアプリケーション |
| 説明 | アプリケーションフォルダの説明文 | (任意の値) |
| APPPATH にディレクトリを追加 ※必須 | アプリケーションパスに追加するかを選択 | チェック |
| APPPATH 内の位置 | アプリケーションパスの参照順を選択 | 最後 |
| プロファイル ※必須 | アプリケーションパスを指定するプロファイルを選択 | edasprof |
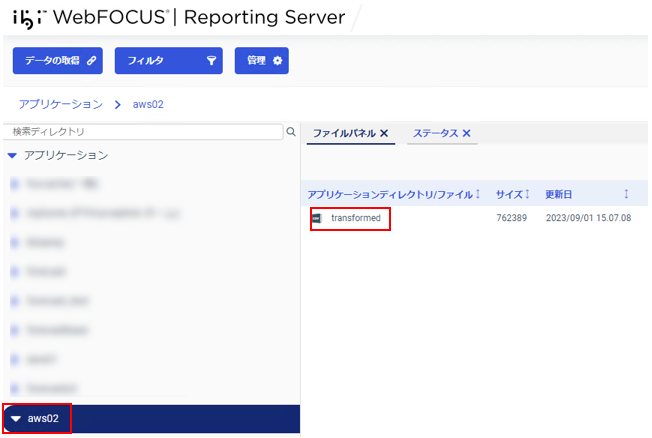
アプリケーション一覧にフォルダが作成されていること、フォルダをダブルクリックすると該当csvファイルが表示されることを確認します。
6.シノニムを作成する
S3バケット内のcsvファイルを検索するためのシノニムを作成します。
※予測分析元のデータ(テーブル)のシノニムは作成済とします。
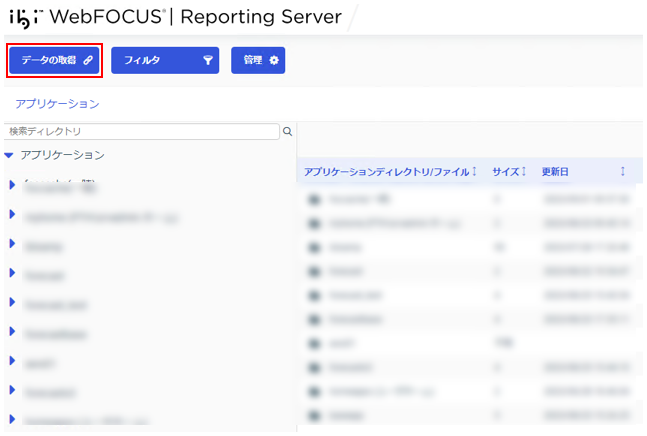
Webコンソールにアクセスし、「データの取得」をクリック。
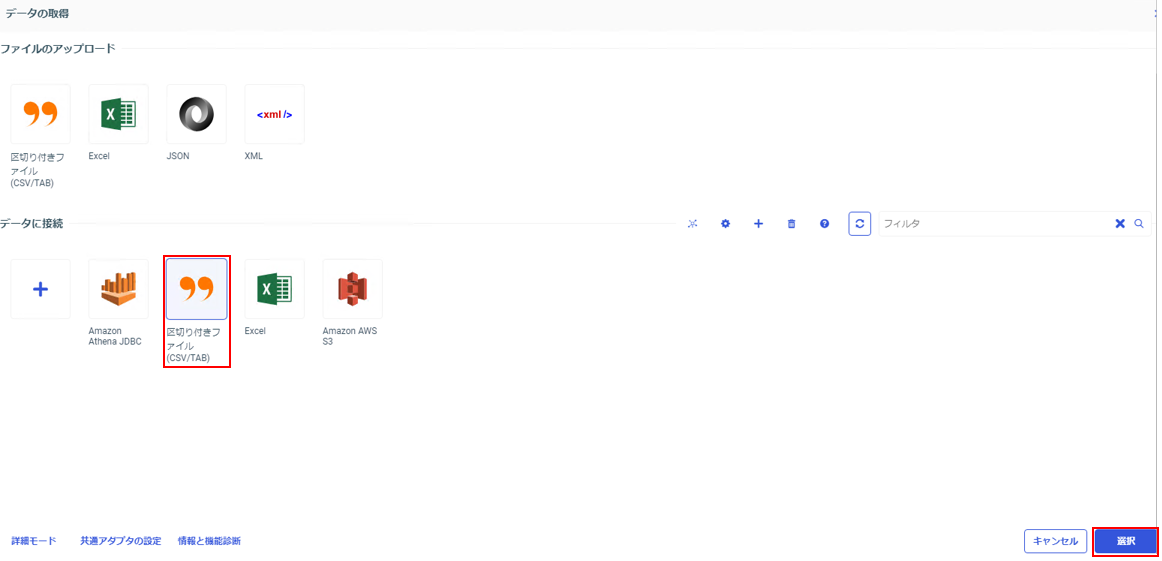
「データに接続」内の「区切り付きファイル(CSV/TAB)」をクリック。
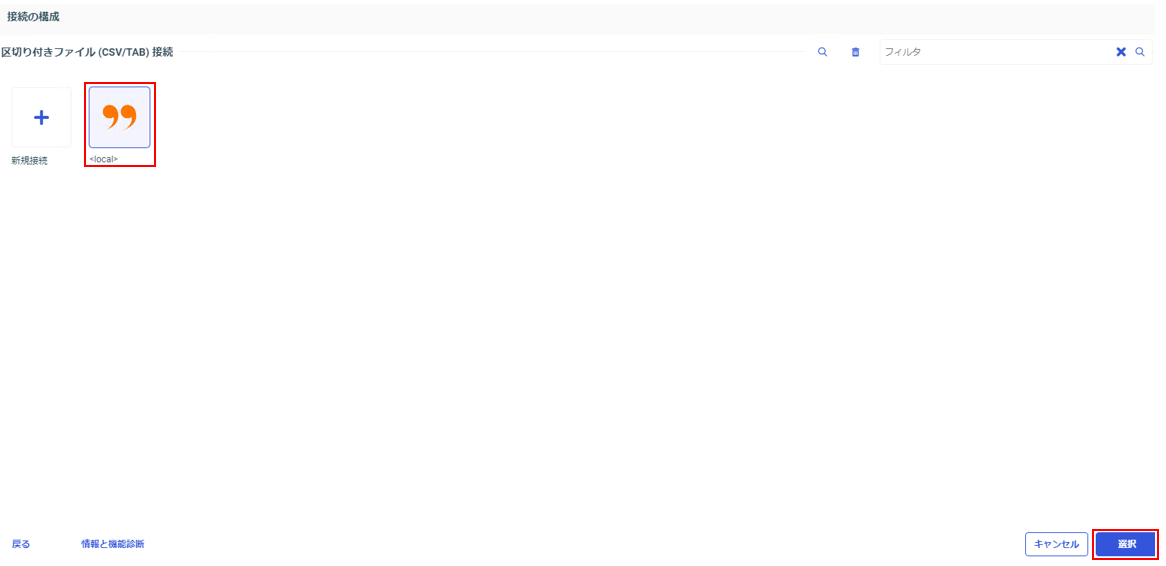
「local」を選択し、「選択」をクリック。
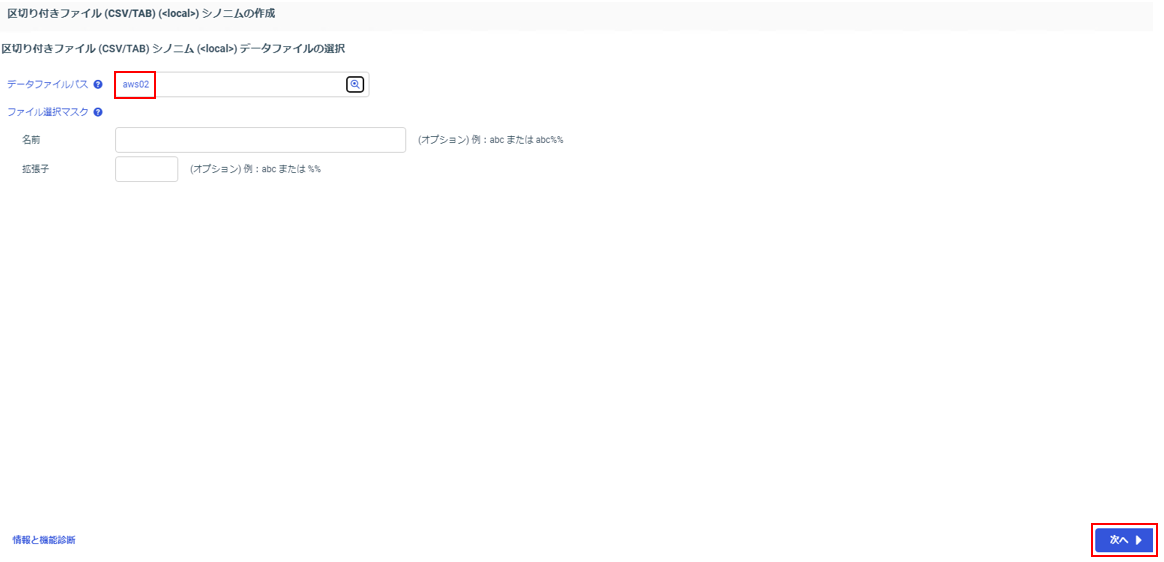
「データファイルパス」に参照先となるアプリケーションフォルダ(aws02)を選択し、「次へ」をクリック。
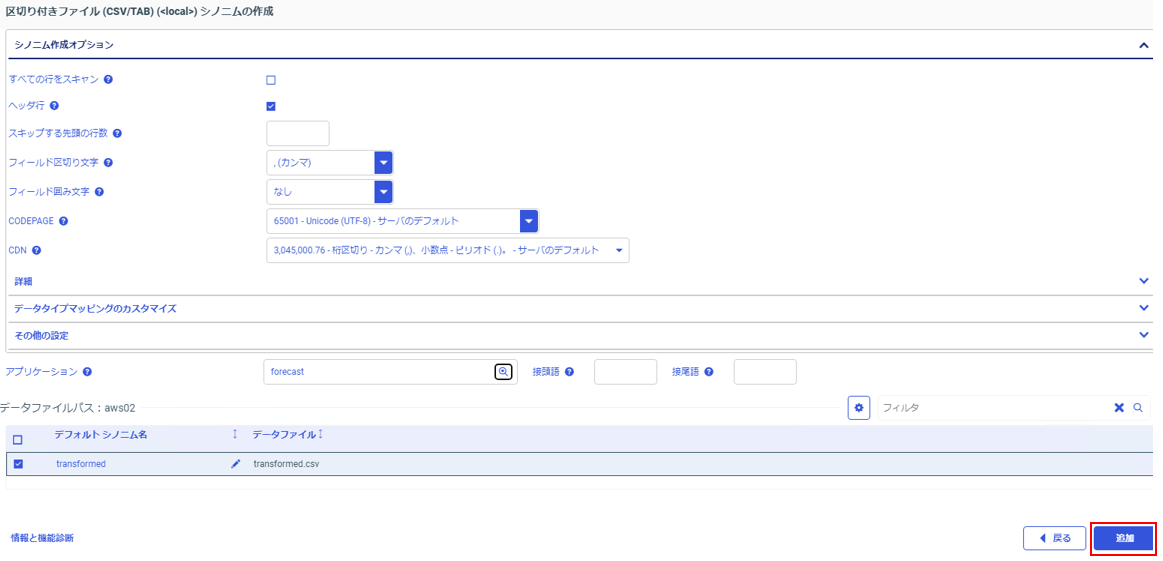
パラメータを入力。
入力が完了したら、「追加」をクリック。
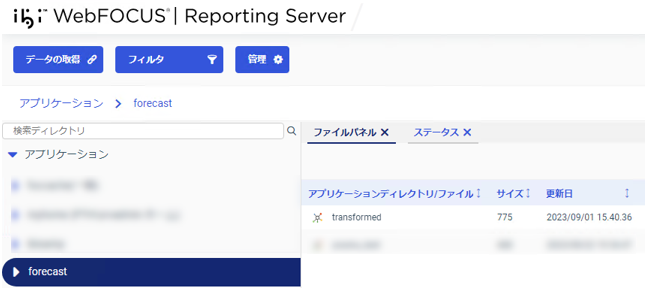
指定したフォルダに、シノニムが作成されていることを確認します。
7.シノニムを編集し一時項目を作成する
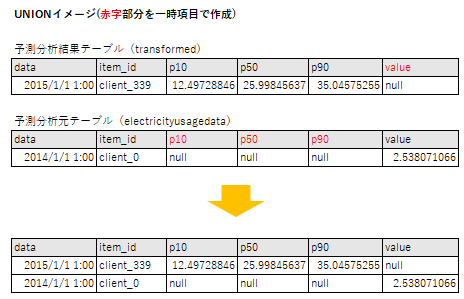
予測分析元の項目とUNIONするためにはUNIONする項目が存在していることや、フォーマットが一致している必要があります。
そのため、一時項目を作成してUNIONの条件を満たすように編集を行います。
※必要に応じて予測分析元のシノニムも編集が必要な場合があります。
該当のフォルダを右クリック-「開く」をクリック。
シノニム名の部分を右クリック-「新規式」-「一時項目(DEFINE)の詳細設定」をクリック。
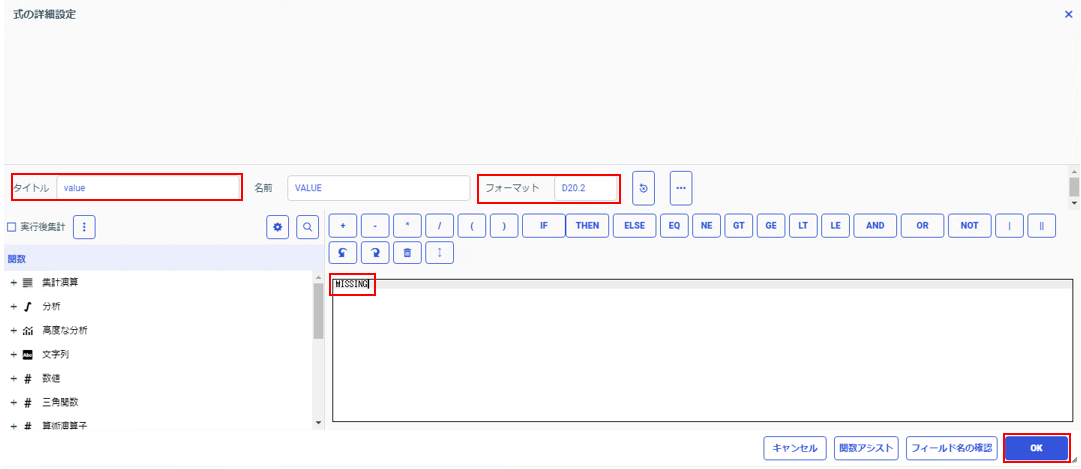
「タイトル」(value)、「フォーマット」(D20.2)、式(MISSING)を入力して「OK」をクリック。
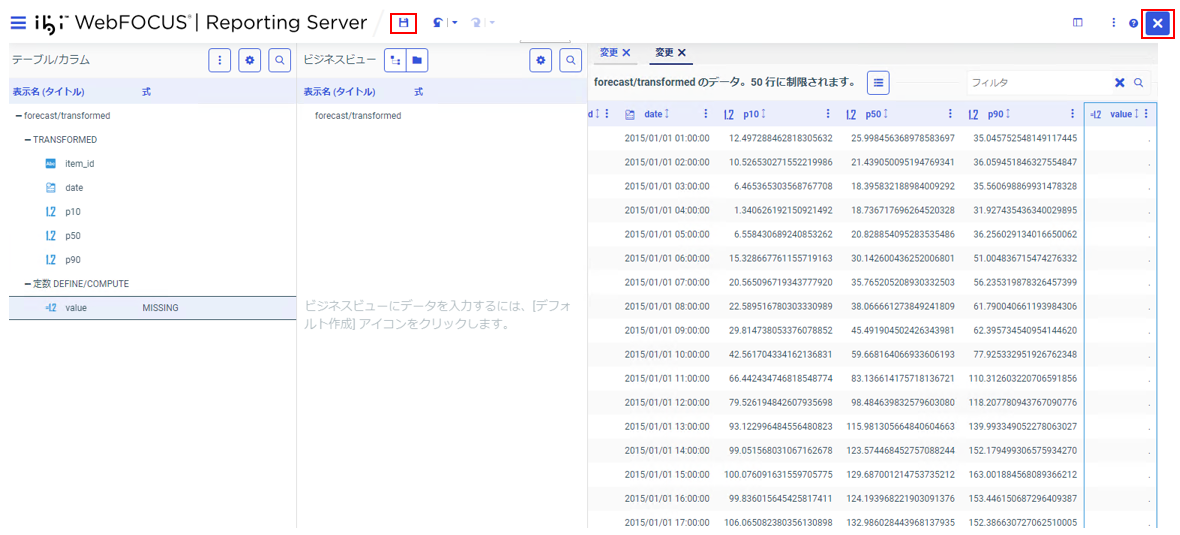
「保存」アイコンをクリックして保存後、「終了してフルコンソールにも戻る」(☓のアイコン)をクリック。
補足:本手順では予測分析元のシノニムも編集します。
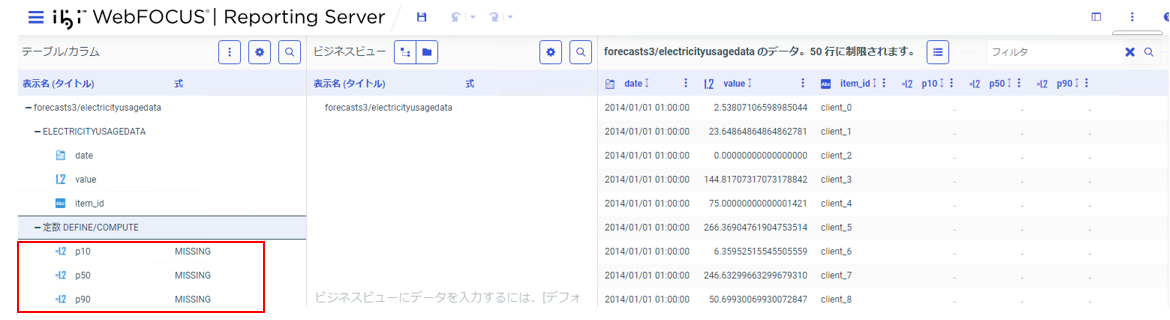
「transformed」シノニムにのみ存在している3つの項目を、NULL(MISSING)とする一時項目を作成します。
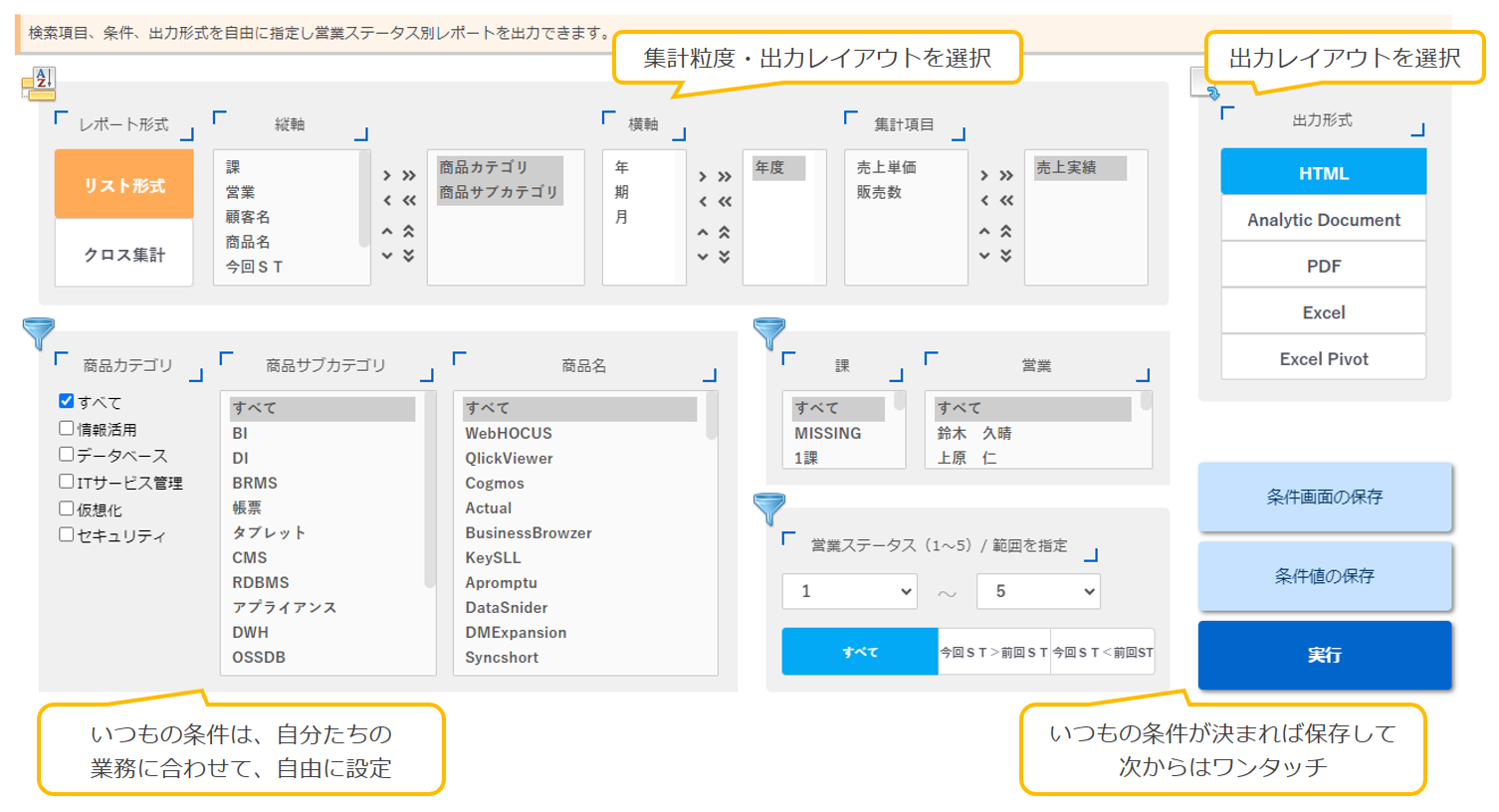
8.DesignerでUNIONを実施する
Designerで予測分析元シノニムと予測分析結果シノニムを結合(UNION)します。
WebFOUCS Hubにアクセスし、「+」アイコンをクリックし、「ビジュアライゼーションの作成」をクリック。
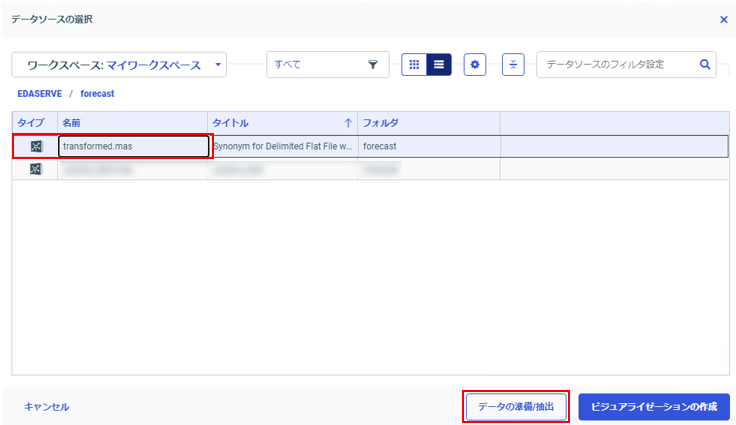
予測分析結果シノニム(transformed.mas)を選択し、「データの準備/抽出」をクリック。
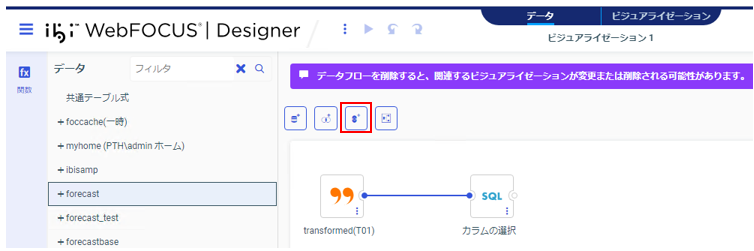
「UNIONの挿入」をクリック。
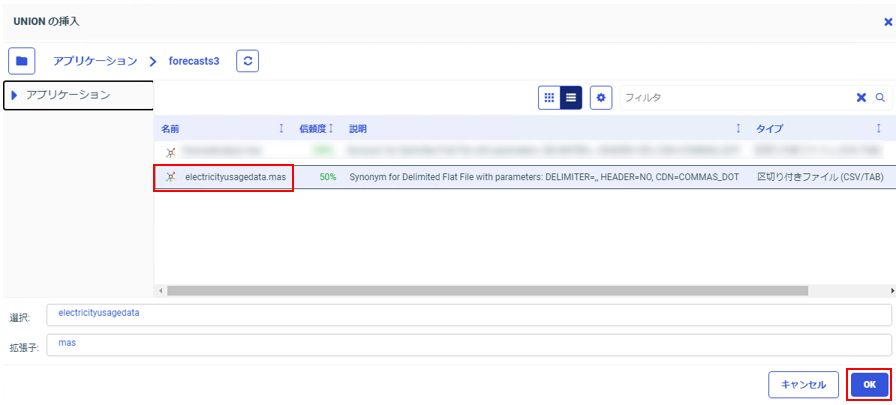
予測分析元シノニム(electricityusagedata.mas)を選択し、「OK」をクリック。
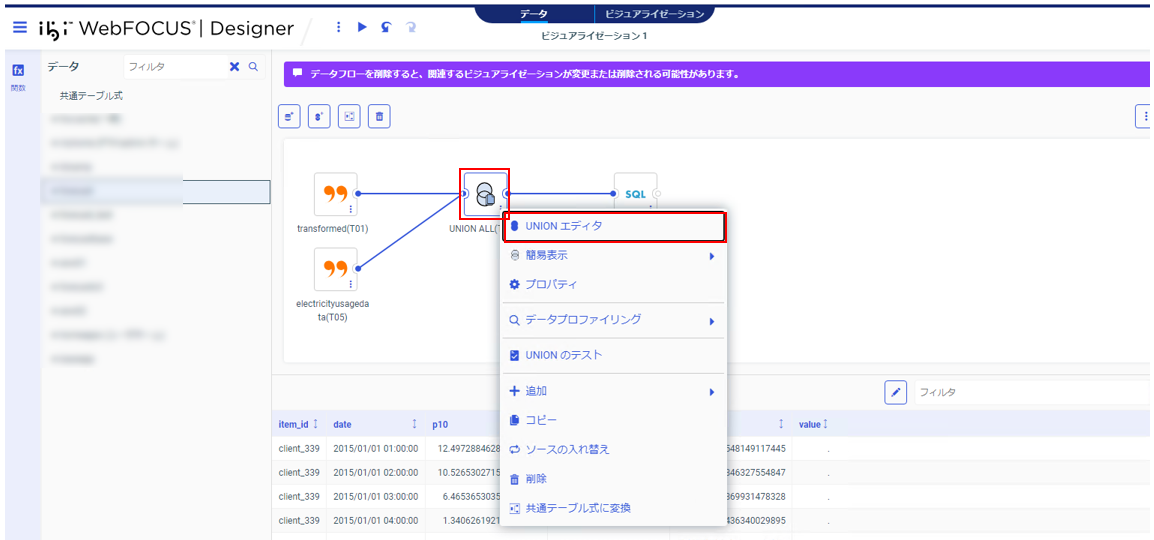
UNIONのアイコンを右クリック-「UNIONエディタ」をクリック。
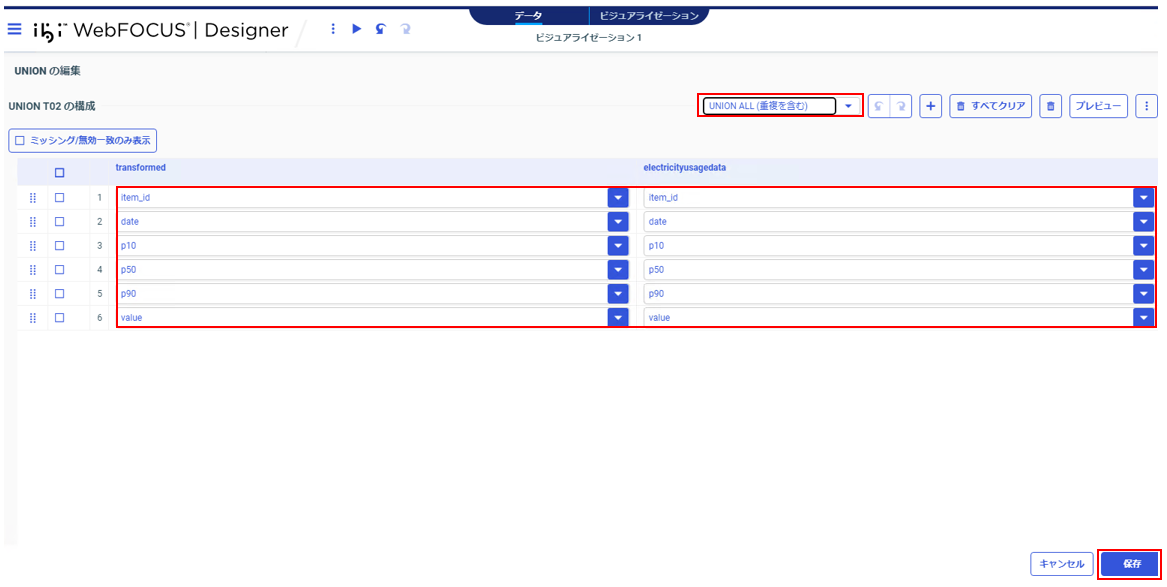
ドロップダウンリストで「UNION ALL(重複を含む)」が選択されていること、UNION対象の項目に問題がないことを確認し、「保存」をクリック。
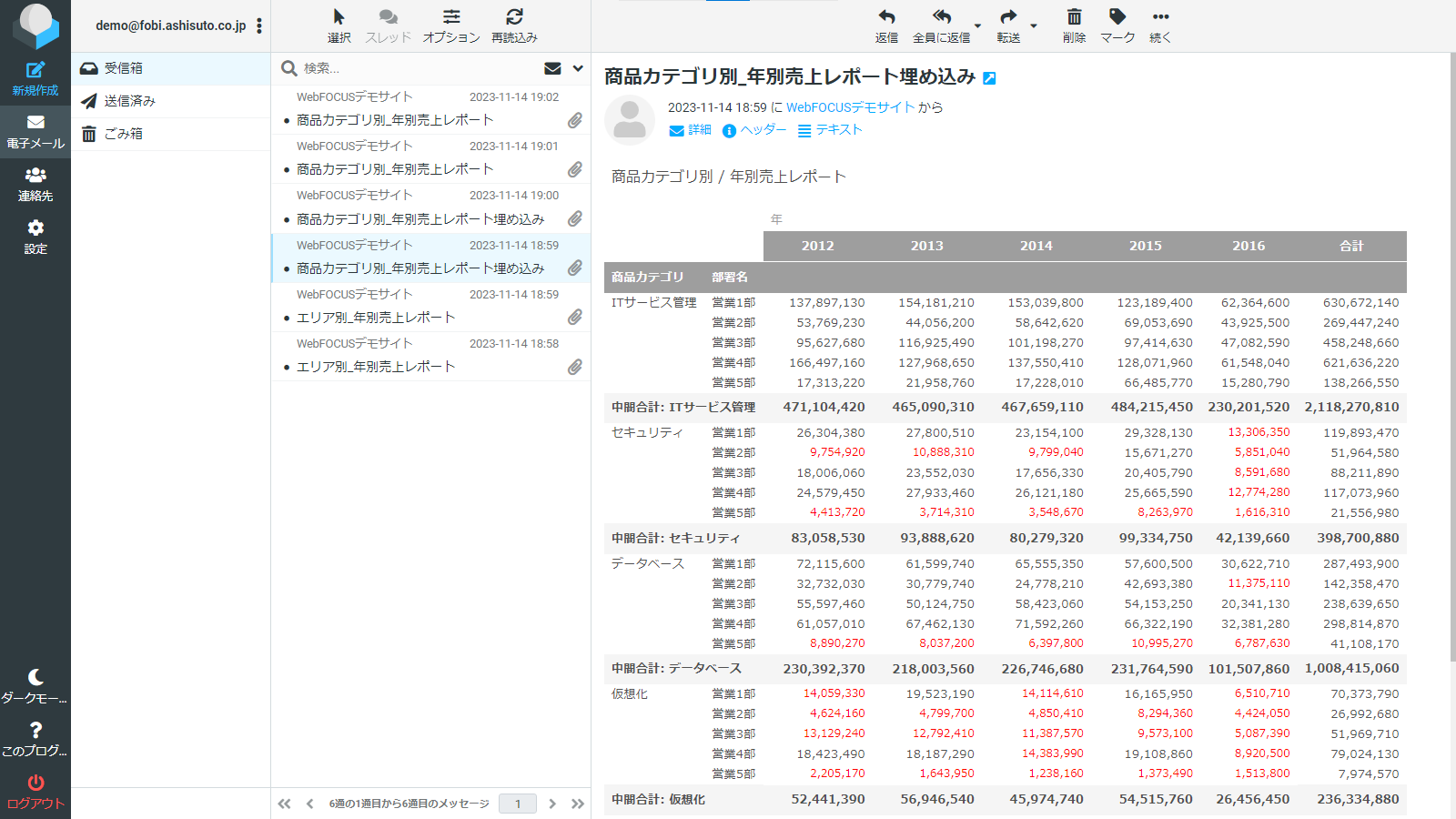
9.Designerでグラフを作成する
フィルタ設定など必要な処理を実施後、Designerでグラフの作成をおこないます。
上部の「ビジュアライゼーション」タブをクリック。
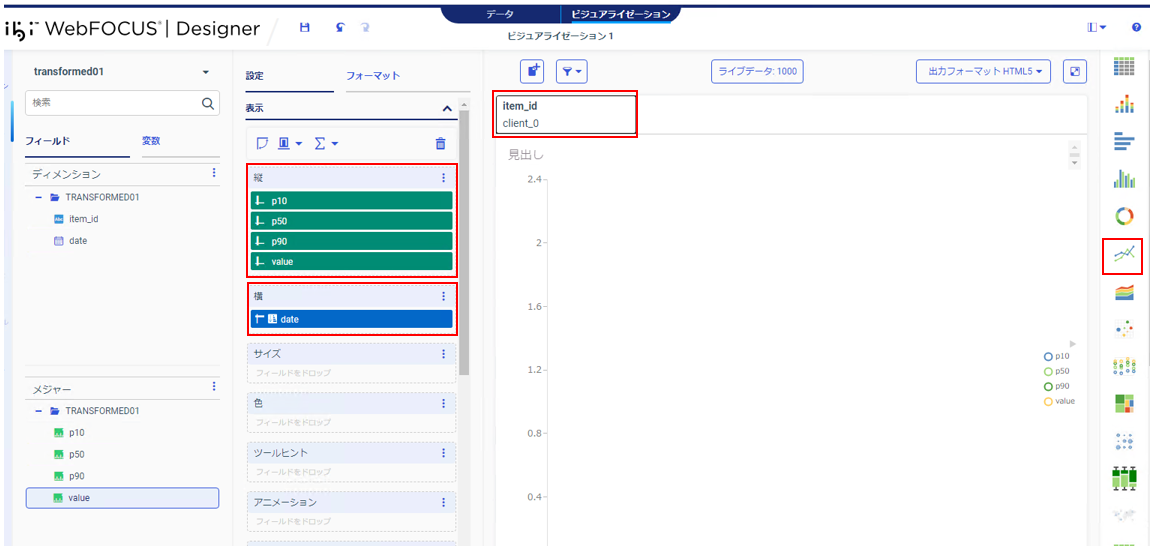
グラフタイプの変更や項目の配置を行い希望のグラフとなるように作成します。左記では以下のように指定しています。
1)グラフタイプ:絶対値折れ線
2)フィルタ:「item_id」
3)横:「p10」、「p50」、「p90」、「value」
4)縦:「date」
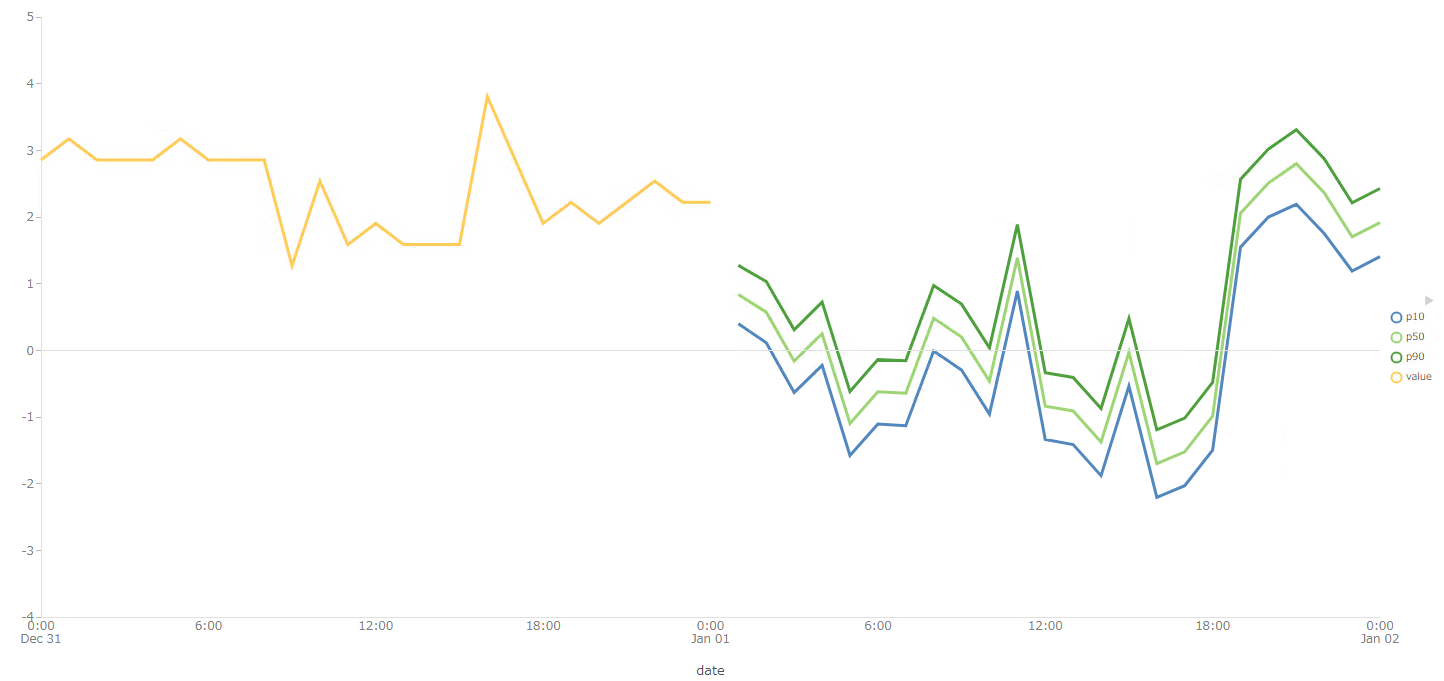
実行して結果を確認します。
オレンジ色の折れ線:予測分析元テーブルのデータ
緑、黄緑、青色の折れ線:予測分析結果テーブルのデータ
予測データが複数あるのは、予測分位数ごとのデータを表示しているためです。
Forecastで予測分析した結果をDesignerで視覚的に表示することができました。
ステップごとに見ると手順を多く感じるかもしれませんが、すべてGUIで完結しているので
操作自体は難しくなく、WebFOCUSに詳しくない方でも始めやすい内容になっていると思います。
予測分析の分野はこれから更に盛り上がってくると思いますので、今後もWebFOCUSを使った活用方法をどんどん発信していきます!
ご要件があればお気軽にお問い合わせください。